I have been talking about  , and how it is useful in decision analysis. How would one, though, estimate from data (for more on this, see e.g. Precup et al. 2000 or Thomas 2015)? Recall that
, and how it is useful in decision analysis. How would one, though, estimate from data (for more on this, see e.g. Precup et al. 2000 or Thomas 2015)? Recall that  is expectation,
is expectation,  pre-tx state,
pre-tx state, 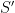 post-tx state,
post-tx state,  a tx,
a tx,  a tx strategy, and
a tx strategy, and  a reward.
a reward.
If you could just try out, you could just take actions according to 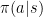 and average the rewards that you observe.
and average the rewards that you observe.
Unfortunately, in medicine, we cannot often just try out a new treatment strategy. Hence, we need to estimate from data that was generated under  (ie, the standard of care).
(ie, the standard of care).
As before (see here for more on this equation) write
Now, multiply the above expression by  where is the standard of care treatment strategy.
where is the standard of care treatment strategy.

Rearrange slightly to note that  can be written
can be written
 which can further be written
which can further be written 
Given  , an estimator for , the last expression can be estimated using data
, an estimator for , the last expression can be estimated using data  that was generated by as (this is an IPW estimator)
that was generated by as (this is an IPW estimator) 

This is a simplified setting, but it is still somewhat magical. It doesn’t come without assumptions, though.
For example, note that if  for any
for any 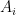 and
and  we are in trouble, because we cannot divide by zero. Actually if
we are in trouble, because we cannot divide by zero. Actually if  for any
for any  and
and  , we are in trouble.
, we are in trouble.
Note also that to estimate  we need to have collected all the covariates,
we need to have collected all the covariates,  that influence both and , since and influence
that influence both and , since and influence  . I will try to give more rationale for this at some point.
. I will try to give more rationale for this at some point.
If one accepts these assumptions (which is a substantial “if”), then one can obtain an expected utility-maximizing treatment policy, 

Leave a comment