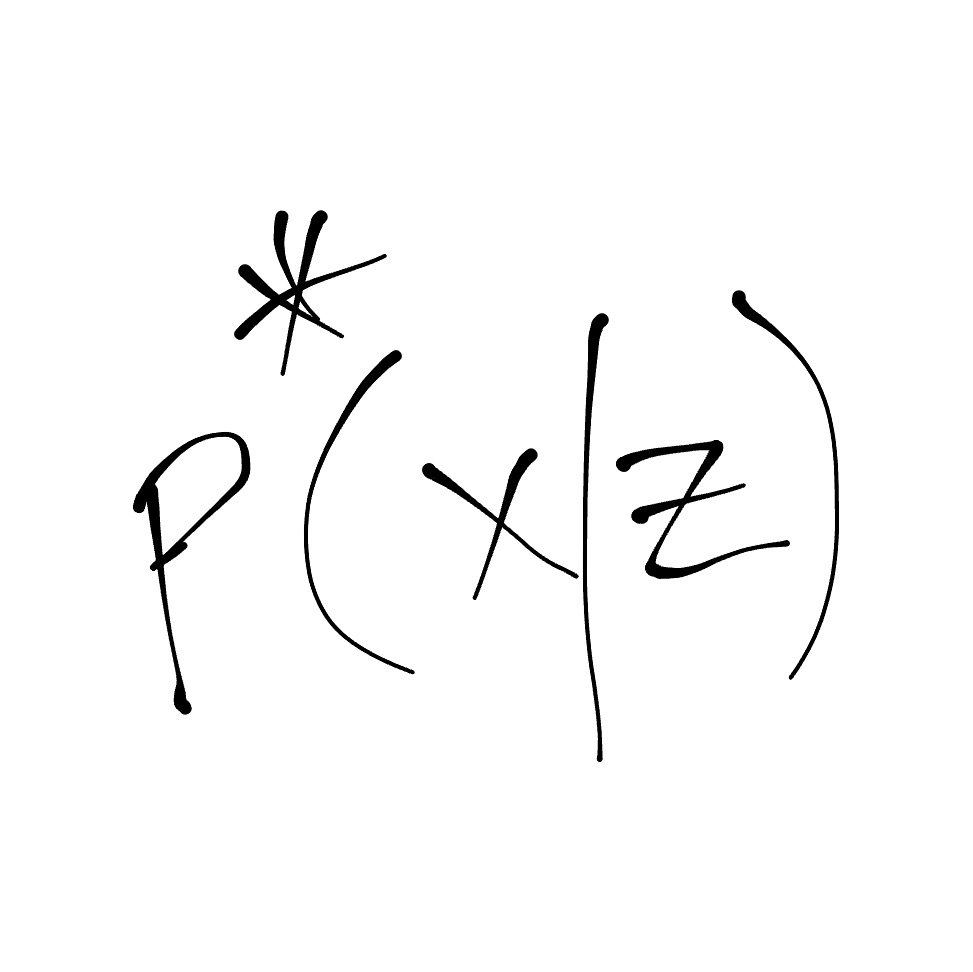

Traditionally, the medical research community has focused on treatment effects (and often the causal inference literature does the same). It is worth exploring the decision problem as well— the patient faces a decision problem, and solving it is often a good way to help them. This motivates much of what is written below. On a somewhat related note, having studied causal inference with fresh eyes not too long ago, certain aspects of it were difficult to grasp. For this, it is possible that taking a decision-oriented perspective might help. If so, it might help others better understand causal inference, which would improve medical research, helping patients a lot.
In this post, I first claim that the policy perspective allows us to derive the adjustment formula using operations from probability alone (I discussed this a bit before, too). Second, I claim that this allows us to think about decision-making in a natural way.
The policy perspective
Let 

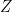

where 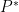
From there, one can derive the adjustment formula found on page 80, equation (3.19), i.e.,

as the special case where the policy 
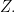
My main contention is that if we start with policies, i.e., with 
Decisions
Now, to see that policies give us a natural way to make decisions, note that we can evaluate any policy, 

where 

We can even obtain a reward-maxizing policy,

an equation which appears, without the interventional framing, in multiple places, including works in decision theory [2] and operations research / reinforcement learning [3,4].
Shark attacks
As an example, suppose a public health department wants to reduce shark attacks, 


The standard approach would be to establish how likely a shark attack would be, given some degree of ice cream intake. I.e., one would target 

This requires “deletion” of the factor 
However, one can use the policy perspective on page 114 to instead write

which reduces to (3.19) upon setting 



Further, suppose the department wishes to determine whether, in order to minimize the expected number of shark attacks, 

Note that




Fortunately, we see that, given heat, ice cream makes no difference. But, if it did, 
References
1. Pearl, Judea. Causality. Cambridge university press, 2009
2. Wald, Abraham. “Statistical decision functions.” Breakthroughs in Statistics: Foundations and Basic Theory. New York, NY: Springer New York, 1950. 342-357.
3. Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. Vol. 1. No. 1. Cambridge: MIT press, 1998.
4. Puterman, Martin L. Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014.

Leave a comment