The question here is whether a model needs to be well calibrated from [0,1] to be useful clinically. For example, consider the case where we need to decide whether to recommend that a patient stay in the ED or be discharged, when there is concern for myocardial infarction. Might a model for this only need to be calibrated in a certain range, such as [0,0.1]? Based on the interesting forum discussion, I will describe my final assessment, which is somewhat evolved from my initial thoughts.
Overall, I think that one should not truncate the range, and if the model does not perform well outside of a certain range, this should be made clear to the end-users. This is because the expected utility of the patient will depend on risk estimates for events (outcomes), and these events will not necessarily correspond to a threshold in the calibration curve. Rather, they are likely a function of the data and the decision problem itself.
Thresholds are alright, as long as they are patient specific (the decision curve analysis threshold is a function of patient utility, and therefore allows for this). However, in theory, at the stage of modeling, as opposed to decision making “in the field,” because there is variability in individual patient utilities (and therefore in the thresholds), there cannot be a global threshold, above which a model need not be well calibrated.
If there is homogeneity in patient preferences, one may be able to get away with a global threshold, but this must be established experimentally, it cannot be assumed, and any particular patient could refute it.
I realize that sometimes one will fit a predictive model and there will not be enough data to estimate a model in certain regions of the calibration curve. This is life. Just make sure the model is not used for situations close to those boundaries, or where the calibration is poor or overly uncertain in general.
As an example, consider a patient who needs to know—with almost certainty—that they have an MI in order to stay in the ED, because the disutility in staying is so high (this might occur with a low risk MI and a patient who has distrust of the healthcare system). Another patient might want to stay no matter what, even if the risk is low. To suit both these patients, the model would need to be well calibrated for high and low probabilities (and anything in between, since most patients fall between these extremes).
This said, MI is a special example, because, for most people, a false negative is very bad, as mentioned by others in the forum. In practice, as I have just done, one can probably make some assumptions about homogeneity of utilities over patients (health is, in my opinion, better behaved in terms of its relationship with utility than are other things). Or, we could say something like — “our model does not give good estimates in your range of interest,” and go from there, as was proposed by others.
However, it’s difficult to do the latter without more studies on how patient utilities are distributed for different problems. Until these distributions are well understood, a threshold during the modeling stage risks removing the patient (perhaps even interfering with patient autonomy). One must instead leave the threshold to be set by the decision makers in the field (as recommended by others) and be very specific about the uncertainty of the calibration estimator over the entire curve. It is natural that a calibration curve be poorly estimated in some areas, as a function of the data.
Either way, my sense is that to compute one’s full expected utility, the model would need to be well calibrated everywhere there is an event (ie, it does not need to be well calibrated for baseline covariates and outcomes that do not exist), because one needs to be able to integrate, within the expectation, over events (there is an interesting duality I think between expected utility integrating over events and the Pauker threshold varying over patients). Computing expected utility can be important, if one wishes to optimize over a policy.
Lastly, take care – while the ED provider is mostly concerned with the low range probabilities needed to make decisions about discharge, the cardiology floor, which has to make decisions about kidney-compromising (sometimes leading to permanent dialysis) angiography, is concerned with probabilities in a higher range. We would not want a model that is not well calibrated in the higher ranges to be accidentally used in the latter case. The cutoff between low and higher range is unclear to me, and may depend on the patient. So, disclosing uncertainty across the model calibration would be helpful.
The following is a compilation of my responses in the forum that led to the conclusion above. They contain some worked examples and more rigorous mathematical arguments.
I originally agreed that for certain prognostic cases, a model that is calibrated only within a certain range may be useful. A model for survival in the setting of an aggressive cancer might only need to be calibrated in the range of low probabilities.
I then stated that for decision making, though, expected utility is a function of the distribution itself, so any estimator of that distribution has to be calibrated everywhere.
Let 







Consider a binary treatment T, patient covariates 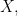






I am also trying to think about whether this is still the case when evaluating some other function of utility besides expectation.
After thinking about this more, I decided that it’s more complicated than what I originally posted. Actually, we only need that 

Consider the example where 




I think overall in this way it is the nature of the probem, as in the example above, that defines the segment of 
Another thing to note, for many decisions, it’s not just the provider who makes the decision—it also depends on patient utility, which depends on patient preferences, which are individual.
At this point, I re-read the OP’s question, and I realized I would need to expand the framework, and maybe I was talking past others for that reason. Overall though, the notation/framework I provided before (not really my own) is very elegant and expressive for these types of problems.
Consider the example given in the forum of orange juice for cancer. To better describe the notation, and my argument (which I had thought aligned with the poster’s conclusion about a “risk range,” but also allowed for this risk range to be a subset of (0,1)), let’s say the following happens.
We run a RCT (in this way, we can avoid bringing counterfactuals into it—actually, I’m not sure we can ever avoid the RCT when decision-making is involved, but that’s another topic) assigning 50 cancer patients to a morning glass of orange juice and 50 to water (orange-colored). Then 

We will then estimate the following: 




Now 
Often, 

Now 

![\pi(T=1)\in[0,1]](https://s0.wp.com/latex.php?latex=%5Cpi%28T%3D1%29%5Cin%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

We only needed 



The range we needed it to be calibrated for was innate to the observed patients in the study. In other words, as mentioned in the forum, it is “the data” that defines the range, and within this range, we need good calibration everywhere necessary to evaluate expected utility.
Having written all this, I saw actually that the OP’s question was slightly different: the OP asks, when there is diagnostic uncertainty about an MI, then what about the calibration of a diagnostic model for this? This is different from the orange juice scenario in which there was uncertainty about the final outcome and a model for this. The outcome in the orange juice example is in the future, 10-year survival. In the OP’s question, the diagnosis is in the past – the MI either happened or it didn’t. I had not thought too much about this problem actually – it’s a related, but different decision problem. I have read Vicker’s paper on prostate cancer as it relates to this.
My sense is that because still one would have to evaluate expected utility, one would still be constrained to have the diagnostic model be well calibrated within a range that is necessary to do so. This range again will be linked to the population under investigation in the decision problem (ie, the population from which the data will be generated), and this may not be between 0 to 1, depending on how how rare the diagnosis is, for example.
I think overall in this way it is the nature of the probem, as in the example above, that defines the segment of 
Overall, I think there are a few interesting things that emerge here, as they relate to calibration.
We have a difference between a model for diagnosis and a model for prognosis, the difference between threshold-based and non-threshold based decision making, the difference between randomized and observational data, and how statistical inference relates to all of it. Overall, it seems that the question on calibration involves all of these things, which makes it particularly difficult to answer.
In the original example, we have a sort of treatment decision (whether to discharge or not) in the setting of a diagnostic problem (whether there is an heart attack). This can be conceptualized, though, with a prognostic model. Suppose we have, for example, information corresponding to an EKG. The treatment decision 




Further, the prognostic model, 
One could focus not on discharge but instead on catheterization, though, and then it is more like the diagnostic problem, where the action is whether or not to do a test (which aligns with whether or not to do a prostate biopsy).
I preface the next paragraph: I wrote it entirely based on the forum discussion, before reading Against Diagnosis (maybe I read part of it many years ago).
We almost always assume that if we can make the diagnosis, heart attack, we are done: then, we just have to treat. It varies by problem. For many medical problems, one is done when one makes the diagnosis, but this may be less about reality and more about the medical community’s historical focus on diagnosis (which may be related to antibiotics). Especially with medical conditions that don’t fit into neat diagnostic boxes, this is incorrect. Rather than worry about diagnosis, we are sometimes better off thinking about what to do given the information that we have. Then, we can focus on the uncertainty about what will happen after we do it. This is what really matters.
The treatment problem is similar I think (maybe the same) as what is called the prediction problem in Against Diagnosis. However I would propose to solve it by finding a policy that maximizes expected utility. In my mind, in this way, with the prognostic orange juice example, and the EKG example above, we make a decision without a threshold.
In my experience, discussing risk estimates can be challenging. For example, with statins, instead of finding a policy that maximizes utility, providers often estimate 10-year ASCVD risk, and if it is greater than or equal to 10%, they recommend a statin. This is the official guideline.
This is problematic, in my opinion. It assumes, among other things, that any two patients experience cardiovascular events and statin side effects in the same way. It also assumes that the information in the ASCVD covariates is sufficient to make a decision.
This is not what is recommended in Against Diagnosis, I realize. Reading it, I also realize that the ASCVD-based approach is an improvement of how things would otherwise be.
It’s ironic, in reading Against Diagnosis, the hope was that ASCVD would move us away from dichotomization, but then ASCVD just somehow became dichotomized.
With respect to inference, I agree. For example, the variance of the posterior of risk might increase as we approach a risk of 1, especially if 10-year survival is rare. Ultimately there is an expectation over utility and then an outer expectation over the risk model. Not an easy problem.

Leave a comment